LEGO - TL;DR
I recently(literally 1 hour ago) came across a research paper on a new type of MLLM,
full information here
https://arxiv.org/html/2401.06071v2 and i tasked my self to write a TL;DR article on everything i read and understood from paper summarized in this in < 1 hour .
Here we go

Problem Statement:
Current MLLMs(Multi modal language models) primarily focus on global information and do not consider fine-grained local information in multi-modal data. This limitation restricts their application in tasks requiring a more detailed understanding.
For example in the image above, it only references the dog in the statement “In the foreground, there’s a happy-looking dog with a white coat sitting among various animals.” It cannot provide exact spatial coordinates of the dog in the image.
E.g.
The dog is located in the top right corner of the image, with coordinates (0.7, 0.8) to (0.9, 1.0). It is a small brown terrier sitting on the grass.
This limitation is present throughout different modalities - Images, Videos (identifying timestamps of an event occurrence), and Audios.
LEGO: Language Enhanced Multi-modal Grounding Model
A unified end-to-end multi-modal grounding model.
LEGO introduces an end-to-end multi-modal grounding model and training methodology to achieve detailed understanding across images, video, and audio using its modular design and large multi-modal dataset.
How LEGO Does It:
- LEGO uses separate encoders and “adapters” for each modality, preserving the unique characteristics of each input type.
- It represents spatial and temporal information directly as numbers in text form, eliminating the need for vocabulary.
- LEGO’s training occurs in three stages: aligning encoders, learning fine-grained understanding, and cross-modal instruction tuning.
- The model’s creators constructed a rich multi-modal dataset for training, addressing the scarcity of relevant data.
- LEGO excels in tasks like image grounding, video temporal grounding, and sound localization, comprehending multi-modal inputs with precision.
Comparison: Current MLLMs vs. LEGO
Example 1: Image Description
Current MLLMs (Global Response):
The image shows a grassy backyard with several animals. A dog is one of the objects in the picture.
LEGO (Fine-Grained Local Response):
The dog is located in the top right corner of the image, with coordinates (0.7, 0.8) to (0.9, 1.0). It is a small brown terrier sitting on the grass.
Explanation:
Current MLLMs provide a general, global response that describes the overall scene but lacks precise localization. In contrast, LEGO’s fine-grained local response not only identifies the presence of a dog but also pinpoints its exact location within the image, providing specific coordinates and detailed attributes.
Example 2: Audio Description
Current MLLMs (Global Response):
The audio clip contains different instruments playing throughout.
LEGO (Fine-Grained Local Response):
The music starts with a piano solo from 30 seconds to 1 minute into the track.
Explanation:
Current MLLMs offer a global response that acknowledges the presence of various instruments in the audio clip but lacks temporal precision. In contrast, LEGO’s fine-grained local response specifies when the piano solo begins and ends, providing precise temporal information, which is crucial for understanding and analyzing audio content.
Training LEGO
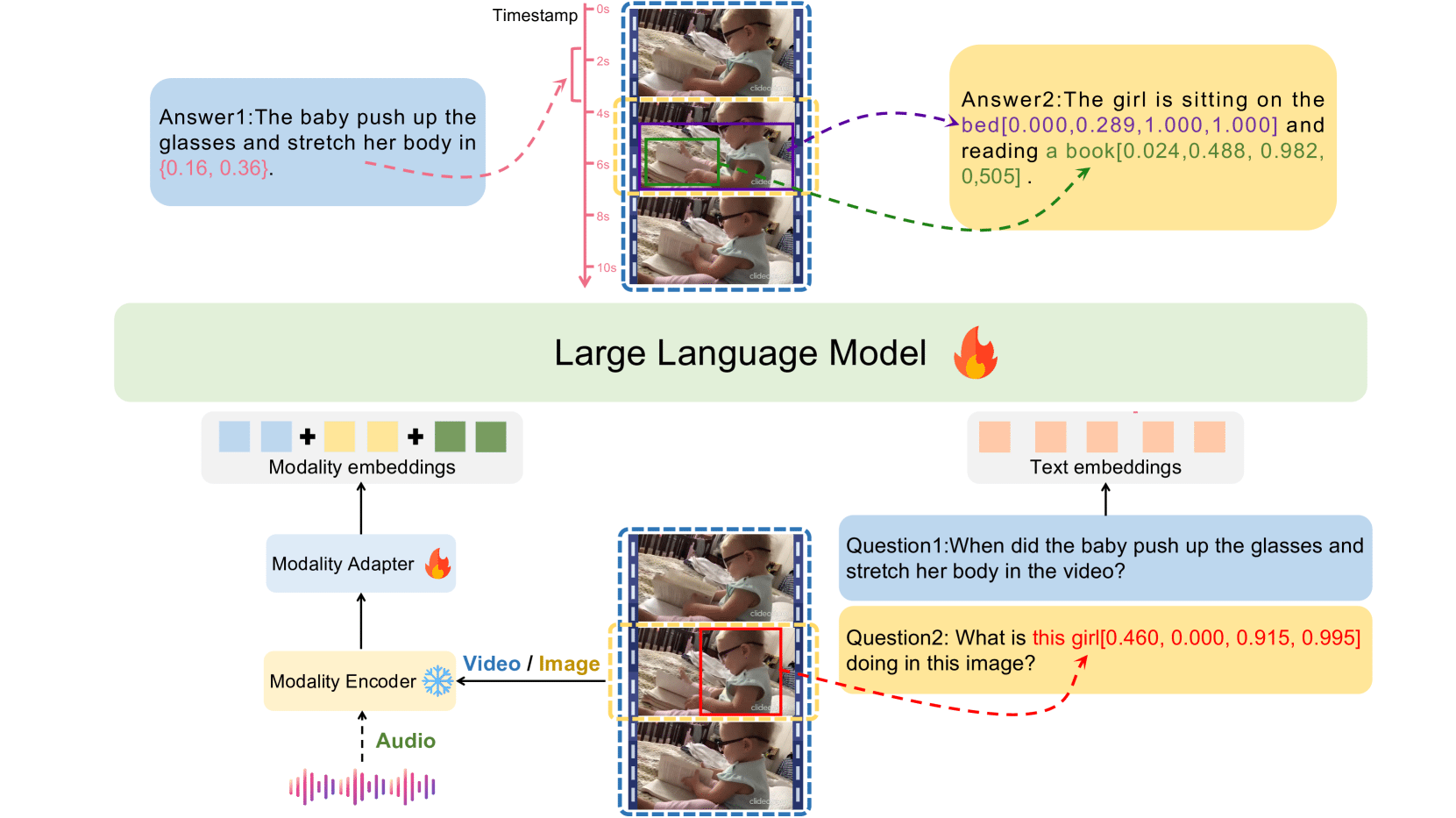
The LEGO model utilizes the Vicuna1.5-7B as the foundational language model. The training approach comprises three stages: multi-modal pre-training, fine-grained alignment tuning, and cross-modal instruction tuning.
Stage 1: Multi-modal Pretraining
In this initial stage, the focus is on enabling the model to comprehend multi-modal inputs through pretraining. The training data primarily consists of public datasets or converted datasets mentioned in section 3.2. During this stage, the Language Model (LLM) and the encoders for each modality remain frozen. Only the adapter parameters for each modality are learned, while the LLM model and modality encoders remain frozen. The training process is conducted with a batch size of 64, a learning rate of 2e-3, and is completed in approximately 10 hours using 8 A100 GPUs for LEGO-7B.
Stage 2: Fine-grained Alignment Tuning
In the second stage, they perform fine-grained alignment tuning to enhance the model’s understanding of spatial coordinates and timestamps. The training data used in this stage is a dataset they constructed, containing the spatial-temporal representation mentioned in Section 3.1.4. During this training process, the encoders for each modality are frozen, while the LLM and adapters are trained. Training is performed with a batch size of 32, a learning rate of 2e-5, and takes around 40 hours using 8 A100 GPUs for LEGO-7B.
Stage 3: Cross-modal Instruction Tuning
The third stage involves cross-modal instruction tuning to further refine the model using generated data. This stage aims to enable the model to generate responses that better align with human preferences and improve multi-modal interactions. They use the instruction-tuning dataset generated as described in Section 3.2 for training. Similar to the second stage, during training, the encoders for each modality are frozen, while the LLM and adapters are trained. The model is trained for one epoch with a batch size of 32 and a learning rate of 1e-5. Training on 8 A100 GPUs for LEGO-7B is completed in approximately 8 hours.
Consistent Training Objective
L(θ) = -𝔼[(x, y) ∼ Dcurrent][log p(y|x)] - α⋅𝔼[(x, y) ∼ Dprevious][log p(y|x)]
To prevent catastrophic forgetting in subsequent training stages, they adopt a sampling strategy that incorporates training data from previous stages. The three-stage training process employs a consistent training objective as follows:
E(x,y)~Dcurrent[log p(y|x)]: This is the expected value of the log likelihood of the model’s predictions p(y|x) over the current training dataset Dcurrent.
E(x,y)~Dprevious[log p(y|x)]: This is the expected value of the log likelihood over the previous training dataset Dprevious.
λ: This is a hyperparameter that controls the weight given to the previous dataset term. It’s typically set to a small value, such as 0.001.
-: The overall loss is
calculated as the negative of the two expected log likelihood terms.
In summary, this loss function aims to maximize the log likelihood of the current training data while maintaining a low loss on the previous training data, controlled by the λ term. This helps prevent catastrophic forgetting and ensures the model continues to perform well on older examples as it is updated on new data. The goal is to minimize this overall loss function during training.
Conclusion
In conclusion, the LEGO model represents a significant advancement in multi-modal grounding. Through a comprehensive three-stage training process, LEGO exhibits its capability to understand multi-modal inputs and performs exceptionally well on various tasks that require fine-grained comprehension.
However, it is important to acknowledge certain limitations. Similar to previous models, LEGO may exhibit language hallucination, occasionally generating content not present in the input or providing inaccurate information.
Another limitation arises from the adoption of a sampling strategy due to computational constraints, which can lead to information loss, particularly when processing longer videos. Future research should aim to develop more efficient modeling approaches to mitigate this limitation.
Additionally, while LEGO excels in multi-modal grounding tasks, it currently lacks the ability to produce more detailed grounding results such as segmentation masks. Future work should explore the expansion of the model’s grounding capabilities to support a broader range of requirements.
In future endeavors, there is a potential to enhance the versatility of models like LEGO by accommodating additional input and output modalities while exploring more sophisticated grounding methodologies.
For a more detailed discussion and in-depth insights, readers are encouraged to refer to the main paper.
https://arxiv.org/html/2401.06071v2