Entropy-aware Adjusted Base Frequency.

At what point does ChatGPT forget the first text in a conversation?
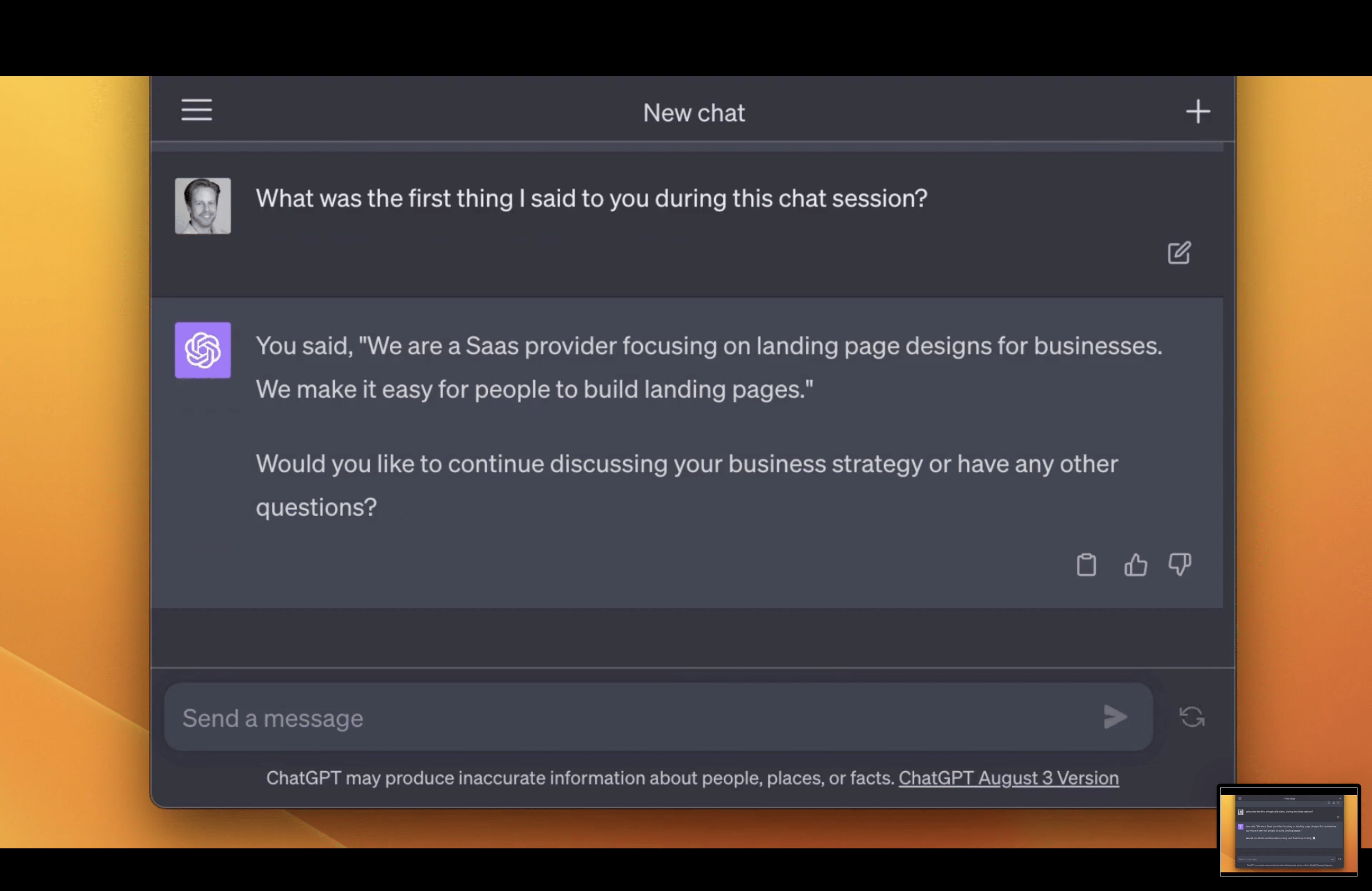
Which is very correct

At 1000 words into the conversation, it still remembers what was said.
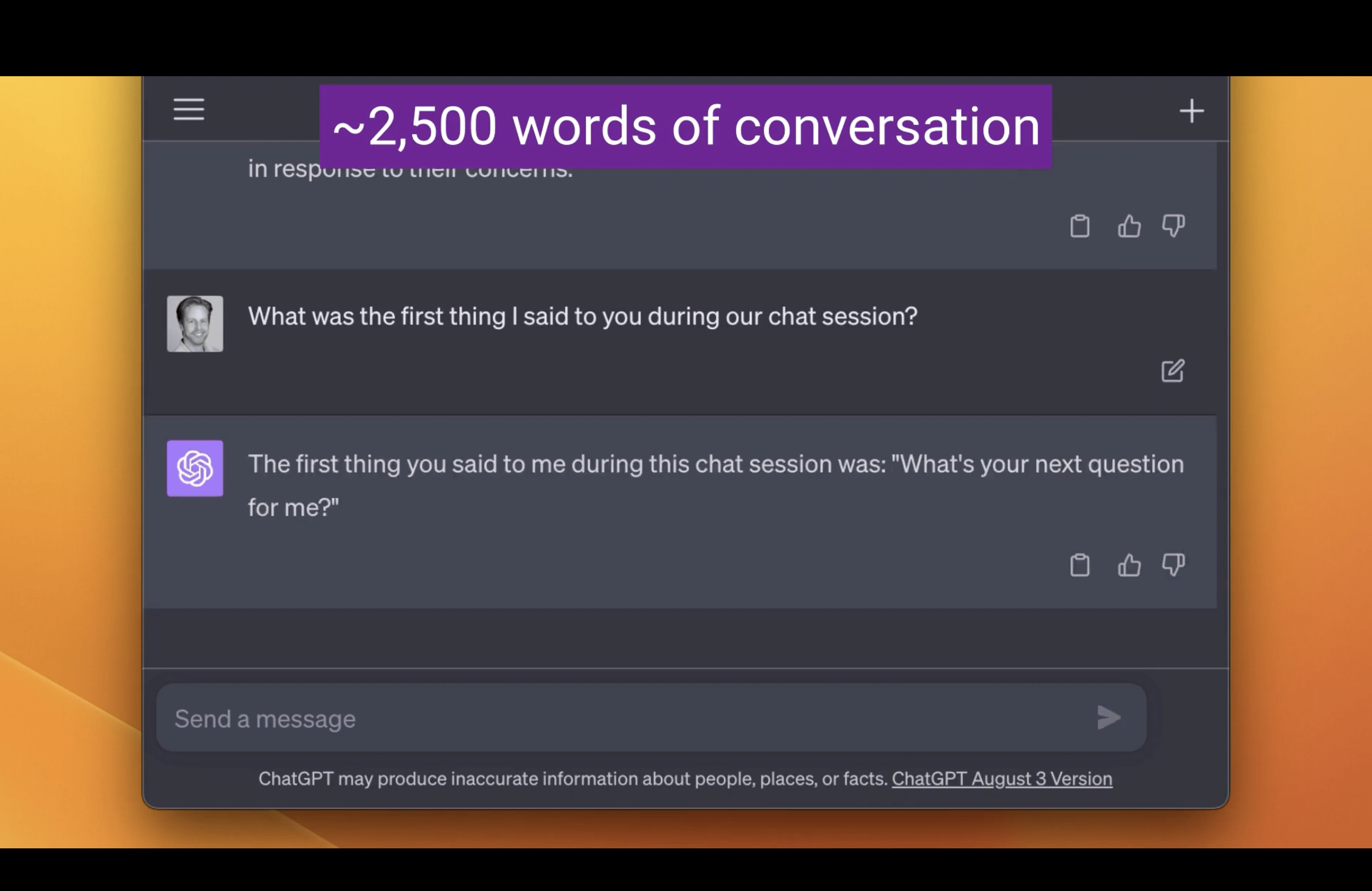
As we approach 2,500 words, it fails to remember, and things start falling apart.
(Please note: The test presented here was directly taken from the video available at https://www.youtube.com/watch?v=MmSMAYooRas but it can be simulated and executed by anyone on ChatGPT at chat.openai.com.)
But why exactly?
Introduction to Context Window
A context window operates by creating a sliding window over the input text, focusing on a specific word at a time. Each word is embedded in a multi-dimensional vector space, allowing the AI model to analyze its contextual associations within the given window. The size of the context window is a crucial parameter, as it determines the scope of contextual information assimilated by the AI system. It refers to the span of text or the number of tokens from the input that the model can consider at once while generating a response.
Advantages and Drawbacks
Pros:
- Enhanced contextual understanding
- Improved language modeling accuracy
- Effective in handling polysemous words
Cons:
- Sensitivity to window size
- Computational overhead in larger windows
- Limited long-range contextual awareness
Every time you send a message to ChatGPT, it passes the full conversation history as input for GPT, the Language Model (LLM), to understand the context/conversation entirely. As the conversation grows, it trims the conversation it sends to GPT (the LLM) to stay within the context window, starting from the top.
When the input exceeds the context window size in LLMs, the model can only consider the most recent tokens up to its maximum limit. Here’s what generally happens:
- Truncation — The model truncates the input, keeping only the number of tokens that fit within its context window. This usually means discarding the earliest parts of the input to make room for the most recent information.
- Loss of Context — Important context from the beginning of the input may be lost, which can affect the coherence and relevance of the model’s outputs.
- Degradation of Performance — The model’s performance may degrade, especially in tasks that require understanding of the full context or where earlier information is crucial to the current response or content generation.
So we can see the context window size is a crucial determinant of how well an LLM can generate coherent and contextually consistent text, as it defines the amount of information the model can consider at any one time during text generation.
Which begs the question how can we extend the context window for LLMs?
In the paper, Extending LLMs’ Context Window with 100 Samples by Yikai Zhang, Junlong Li, and Pengfei Liu, it proposed a new method -
Entropy-aware Adjusted Base Frequency. It is about making LLM better at understanding long sentences or conversations by adjusting how much attention the model gives to each word (Dynamic Attention Scaling), treating different parts of the model differently (Layer dependent), and ensuring that the model can use its previous training while also improving model’s focus on the longer section of the text and tweaking its attention to what is important in the sentence(Facilitate Context Window Extension).
Previous attempts like Position Interpolation (PI) and YaRN have been resource-intensive and lacked comprehensive comparative experiments.
Simplifying the Math #
Let’s break down the math in simple terms. The key idea is to adjust the ‘base frequency’ in the Rotary Position Embedding (RoPE) method. Imagine the conversation as a long road, and each word is a stop along this road. The base frequency adjustment is like changing the speed at which you travel along this road. By tweaking this ‘speed,’ the LLM can ‘travel’ further along the conversation, remembering more of it.
The equation for RoPE, which underlies this concept, is:
RoPE(x,m) = [(x0 + ix1)eimθ1(x2 + ix3)eimθ2…(xd-2 + ixd-1)eimθd/2]
In this equation, x represents the embedding vector, m is the position index in the conversation, and θ_j is defined as b * (-2πj/d). The parameter b refers to the base frequency in RoPE. Modifying b, the base frequency, fundamentally influences how the model interprets the position of each word, enhancing its capability to manage longer sequences.
Comparison with Previous Methods #
Unlike previous methods such as Position Interpolation (PI) and YaRN, which were resource-heavy and lacked comprehensive experiments, this new approach is more efficient. It extends the context window with only 100 samples and a few training steps, making it a significant advancement in LLM technology.
Implications and Future Directions #
This development has exciting implications. It means that models like ChatGPT can handle longer conversations more effectively, remembering and using more of the context. This could lead to more coherent and contextually rich interactions in various applications, from customer service to storytelling.
In conclusion, the paper presents a promising direction for overcoming one of the fundamental limitations of current LLMs. By extending the context window effectively and efficiently, we can expect to see LLMs that are more adept at handling complex, long-form conversations, which is a big step forward in the field of AI and natural language processing.
Additional Points from the Paper #
The paper also highlights the importance of data efficiency. The method demonstrated remarkable results with just 100 samples, a relatively small amount by machine learning standards. This efficiency means that the method can be applied more broadly, even in scenarios where computing resources are limited.
Moreover, the paper explores the impact of different training curricula and data compositions on extending the context window. This exploration is crucial because it shows that the method isn’t just a one-size-fits-all solution but can be adapted and optimized based on specific use cases and requirements.
Looking to the Future #
The road ahead is exciting. This research lays the groundwork for future advancements in AI. We can anticipate more sophisticated and nuanced AI interactions, blurring the lines between human and machine communication. The potential for AI to assist in complex problem-solving, personalized interactions, and advanced content creation is enormous.
Conclusion #
In conclusion, the paper by Zhang, Li, and Liu is a significant step forward in the field of AI and natural language processing. It addresses a fundamental challenge in LLMs and opens up new possibilities for their application. As we continue to explore the capabilities of AI, this research will undoubtedly play a pivotal role in shaping the future of AI interactions and applications.
Paper:
https://arxiv.org/pdf/2401.07004.pdf…
Github:
https://github.com/GAIR-NLP/Entropy-ABF